Barry-Wehmiller gains confidence to expand Microsoft Copilot while reducing oversharing risk across terabytes of legacy data
Cascade Environmental secures CMMC-regulated data and prepares for responsible Copilot deployment with Opsin
Culligan securely scales Copilot adoption while reducing AI data exposure by 80%
Encore Technologies strengthens data controls and confidently deploys Microsoft Copilot with comprehensive security assessment
UiPath secures ChatGPT Enterprise deployment with proactive AI agent governance
Wellstar Health System secures healthcare data and enables confident Copilot expansion with Opsin





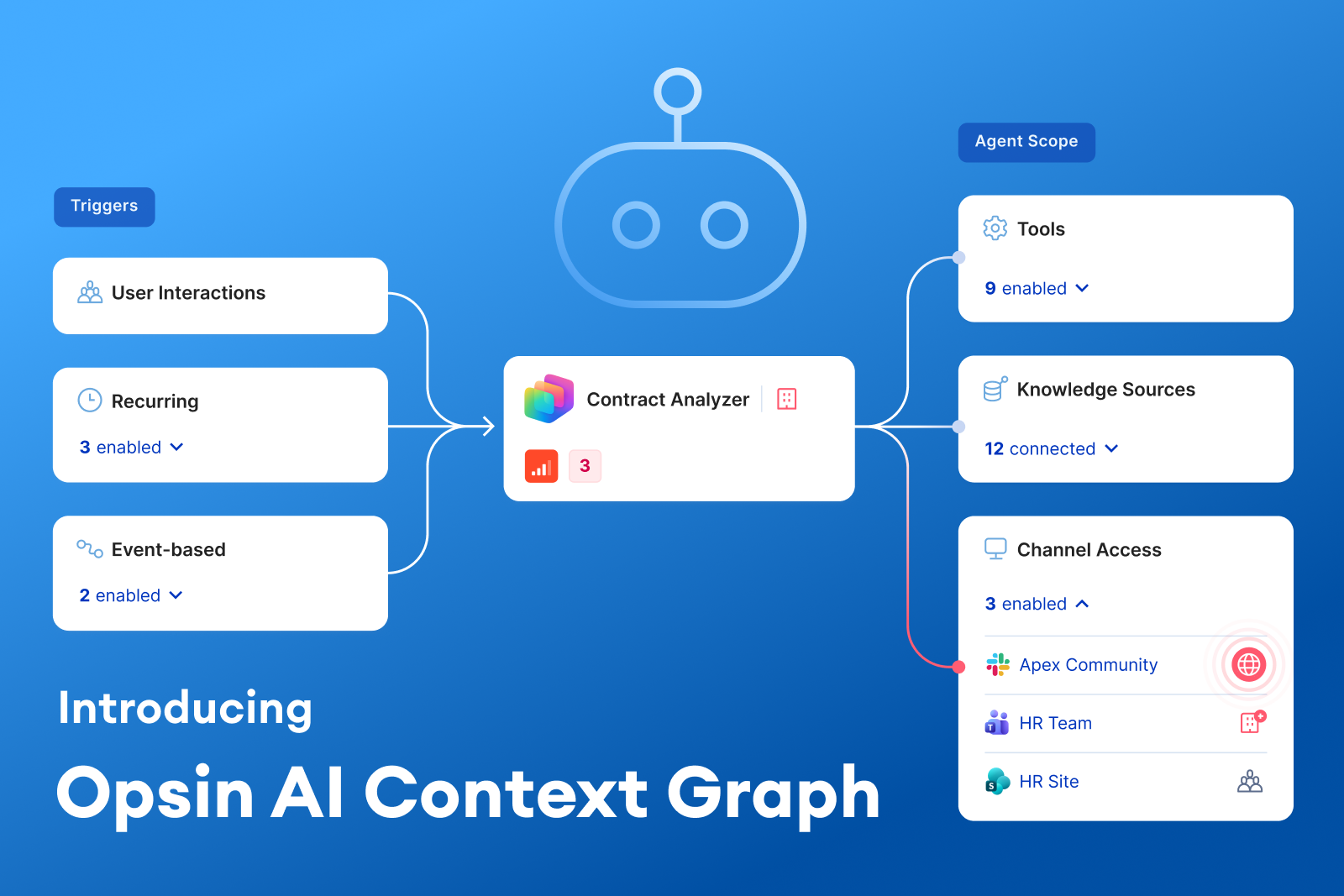


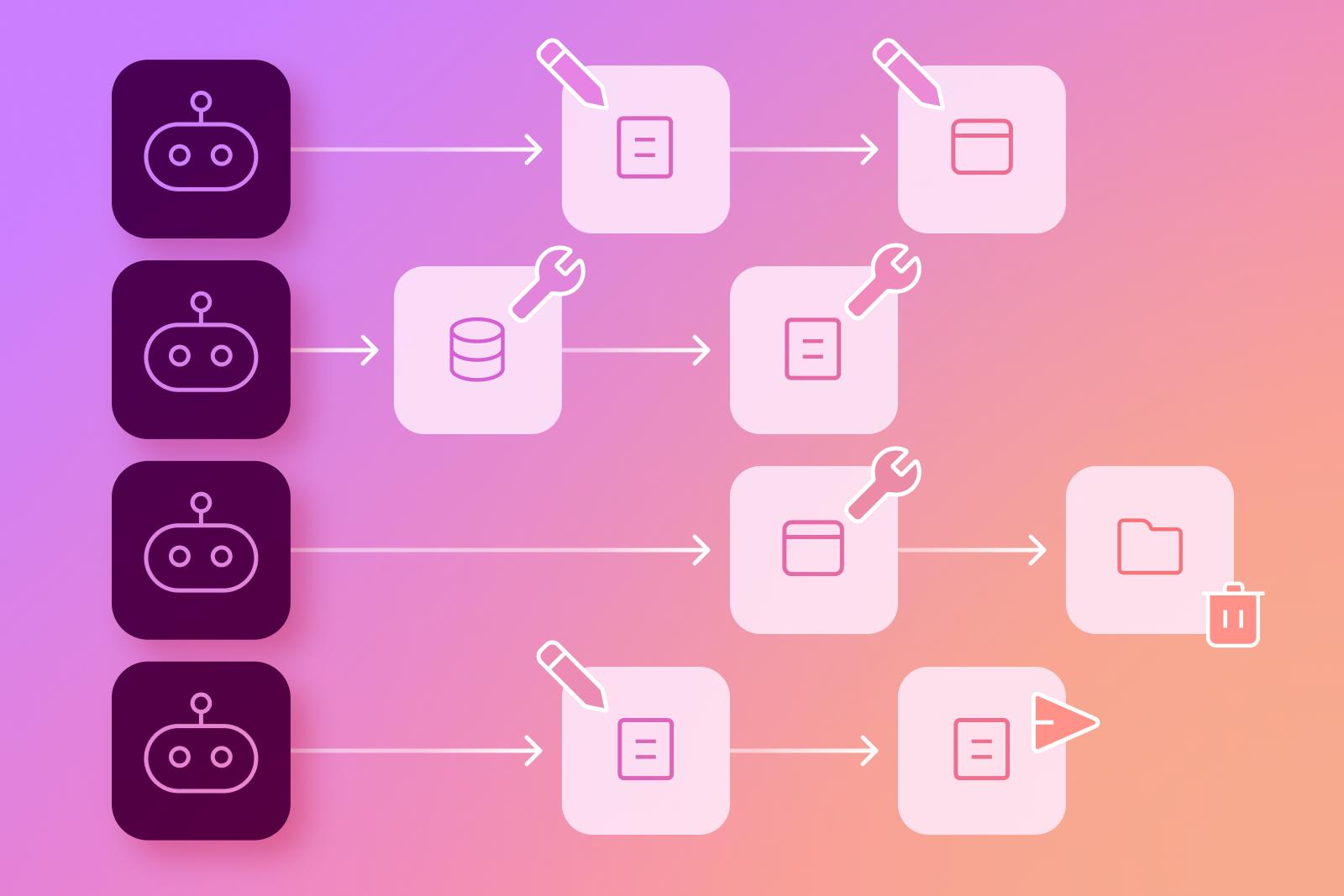

.webp)